Implementing the Dynamic Programming Algorithm with Value Iteration in a Toy MDP
Introduction
Over the past few months I’ve been getting up to speed on the theory of multi-agent reinforcement learning, starting from the fundamentals of single-agent RL.
Here is the link to the MARL book for anyone reading that wants to read through the theory of what I am about to implement (This is specically from sections 2.4 and 2.5).
Fundamentally, I believe theory becomes useful once you can implement it, test it, and see its consequences in a concrete example/model. In this post I implement my first planning algorithm from the MARL book: Dynamic Programming, using Value Iteration on a small toy Markov Decision Process (MDP).
Even though Dynamic Programming does not learn from interaction (it assumes the MDP is fully known), it is a foundational building block, as it shows how an optimal policy emerges from applying the Bellman optimality operator recursively.
To keep the mechanics visible, I built a toy environment inspired by Indiana Jones: a single-lane, five-state corridor with a treasure at one end and a trap at the other. The agent can move left or right, but actions are stochastic, in the sense that sometimes it can slip and move in the opposite direction. The goal here is for the agent to reach the treasure, without falling into a trap. In order to do so, it needs to learn an optimal policy to reach the treasure.
I use Value Iteration rather than Policy Iteration because it is simpler to implement and, in many settings, scales more cleanly as the number of states grows.
Since Dynamic Programming requires a complete specification of the MDP, I define the corridor by its state space, action space, transition model, rewards, and discount factor below:
Defining the Toy Markov Decision Process (MDP)
This environment is deliberately small. I wanted to do several calculations by hand to sanity-check my code and to develop an intuition of how value iteration is being computed under the hood.
State Space
We define a finite set of states:
\[ S = \{0, 1, 2, 3, 4\} \]
- State 0 is a terminal trap (absorbing, negative reward)
- State 4 is a terminal treasure (absorbing, positive reward)
- States 1, 2, 3 are non-terminal corridor states
Action Space
At every non-terminal state, the agent may choose:
\[ A = \{\text{left}, \text{right}\} \]
These actions attempt (we use ‘attempt’ here because of the stochasticity within our MDP) to move the agent along the corridor.
Transition Model
This world is stochastic, meaning that the agents intended actions do not always happen. In this case, the corridor is slippery, and as a result he may slip and move in the other direction.
For any non-terminal state:
\[ \tau(s' | s, a) = \begin{cases} 0.8 & \text{if } s' \text{ is the intended direction} \\ 0.2 & \text{if } s' \text{ is the opposite direction} \end{cases} \]
This introduces uncertainty and forces the agent to reason in expectation (i.e. most of the time it will go where intended, but sometimes, it may slip and move in the other direction).
Reward Function
The agent shall be rewarded with ‘+1’ when it reaches the treasure. If it becomes immobilised during its expedition, then it receives a reward of ‘-1’. Furthermore, there is a ‘living cost’, which is a very small negative value. The reason for the reward being negative is so the agent understands there is a cost for wandering, and thus is motivated to choose shorter paths.
\[ R(s, a, s') = \begin{cases} +1 & \text{if } s' = 4 \\ -1 & \text{if } s' = 0 \\ -0.04 & \text{otherwise} \end{cases} \]
Discount Factor
Future rewards are discounted by:
\[ \gamma = 0.95 \]
Visualization of Environment
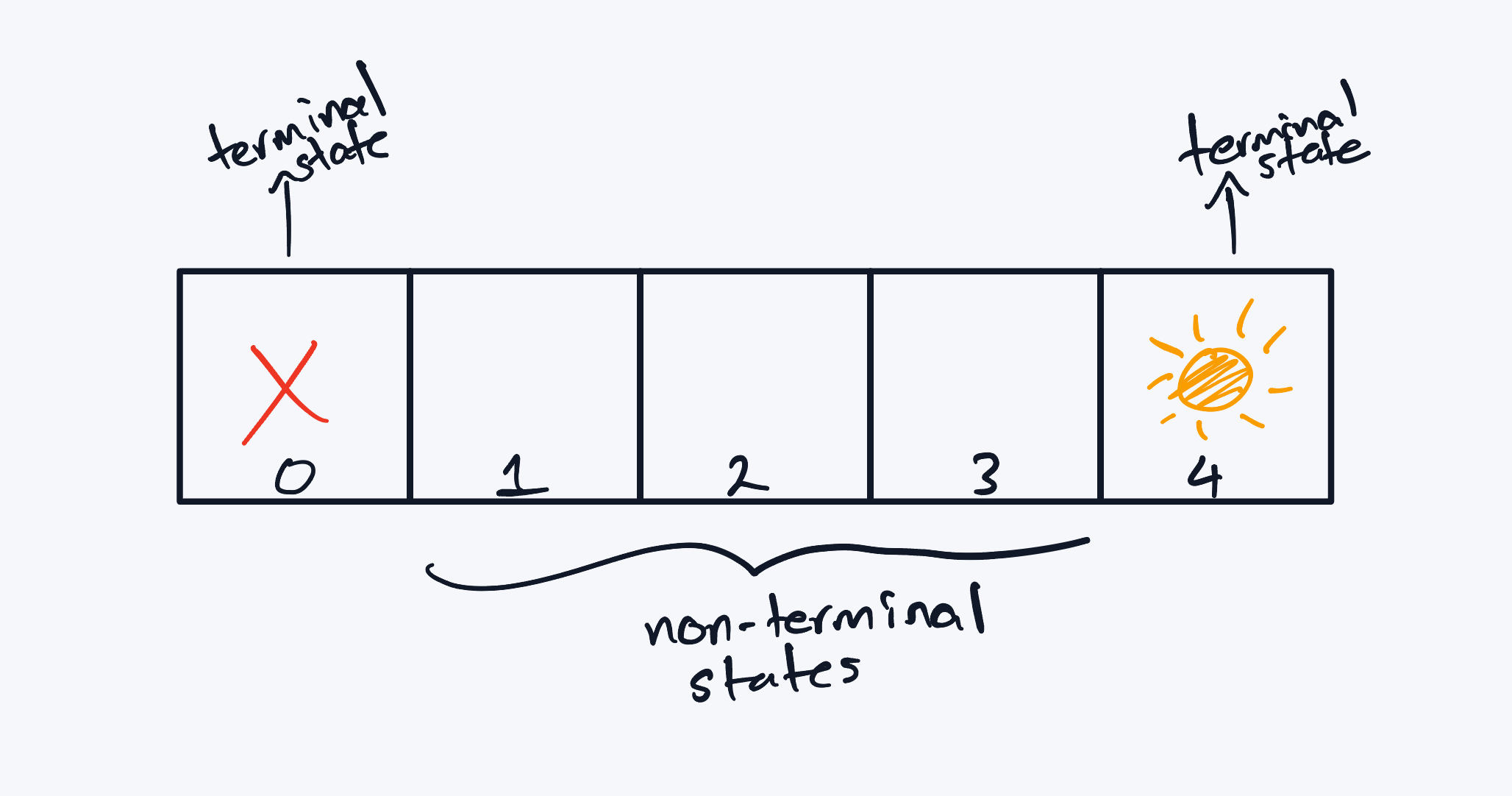 The 5-step corridor environment. The agent moves left or right with stochastic transitions and terminal states at both ends.
The 5-step corridor environment. The agent moves left or right with stochastic transitions and terminal states at both ends.
Defining the Problem
In this RL problem, at a high-level, we need the agent to reach the treasure, without landing on the trap and becoming immobilised. Technically, this translates to an objective of obtaining the optimal policy which I define as the set actions that the agent should take in every state, such that it maximises the sum of its expected future discounted returns. The natural question then becomes: ‘how do we find this optimal policy’?
Rather than solving for the policy directly, we first solve for a proxy, called the Optimal state-value function. which assigns to every state, the expected return for the agent acting optimally. Essentially, this function assigns, to every state, the expected return the agent would receive if it were to act optimally from that state onward. Intuitively, this tells us how “good” each state is under the best possible behaviour.
Once we have this function, extracting the optimal policy becomes straightforward. For each state, we simply iterate through all the actions and choose the action that maximises the corresponding action-value function - which corresponds to the optimal state-value function, as the optimal state-value function is defined as the maximum of the action-value function…In other words, the action that leads to the highest expected future discounted return from that state. Thus, the optimal policy is the collection of these maximising actions, one for each state in the state space. Intuitively, I like to think about it like an instruction manual which shows the best action you can take in a specific scenario.
The algorithm I use to compute this optimal state-value function is Value Iteration, which repeatedly applies the Bellman optimality operator until the values stop changing. I will go into some detail as to why this works Mathematically. For now, let’s state the algorithm, as per the MARL book, and implement this in Python. In doing so, we can obtain a strong intuition as to how the theory works in practice, which leads to a stronger understanding of the concept from first principles.
Algorithm: Value Iteration for MDPs
Initialize:
\[ V(s) = 0 \quad \text{for all } s \in S \]Repeat until \(V\) converged:
We apply the Bellman optimality operator as follows:
For all \(s \in S\), \[ V(s) \leftarrow \max_{a \in A} \sum_{s' \in S} \tau(s' \mid s, a)\Big(R(s, a, s') + \gamma V(s')\Big) \]
- Return optimal policy \(\pi^{*}\) with, for all \(s \in S\), \[ \pi^*(s) \leftarrow \arg\max_{a \in A} \sum_{s' \in S} \tau(s' \mid s, a)\Big(R(s, a, s') + \gamma V(s')\Big) \]
Full Python Implementation (Value Iteration)
Now, I shall implement the algorithm in Python. For anyone curious and wanting to implement the code yourself, I recommend going through the code section by section to understand what is being done, and then writing the code line by line, and lastly (which I think is the most important part), implement the code base yourself from scratch.
It builds the transition tensor \(\tau(s' \mid s,a)\) (which is the probability distribution for the transition process), the reward tensor \(R(s,a,s')\) (which specifies the immediate reward received when the agent takes action \(a\) in state \(s\), and transitions to the next state \(s'\)); performs value iteration (as per the algorithm above), and then extracts the greedy optimal policy, with respect to \(V^{\pi}\) for all \(s \in S\).
import numpy as np
# --------
# MDP Setup
# --------
S = 5 # we have 5 states
A = 2 # 2 actions: left and right
LEFT, RIGHT = 0, 1
terminal_states = {0, 4}
gamma = 0.95
p_intended = 0.8
p_slip = 0.2
living_cost = -0.04
def is_terminal(s: int) -> bool:
"""Check whether we are in a terminal state."""
return s in terminal_states
def next_state(s: int, action: int) -> int:
"""
Terminal state is absorbing.
Otherwise next state is s-1 (LEFT) or s+1 (RIGHT).
"""
if is_terminal(s):
return s
return s - 1 if action == LEFT else s + 1
# --------
# Build out Transition Distribution and Reward Table
# --------
Tau = np.zeros((S, A, S))
R = np.zeros((S, A, S))
def create_TauR():
for s in range(S):
for a in range(A):
if is_terminal(s):
Tau[s, a, s] = 1.0
R[s, a, s] = 0.0
continue
INTENDED = LEFT if a == LEFT else RIGHT
SLIP = RIGHT if INTENDED == LEFT else LEFT
sp_intended = next_state(s, INTENDED)
sp_slip = next_state(s, SLIP)
Tau[s, a, sp_intended] += p_intended
Tau[s, a, sp_slip] += p_slip
for sp in [sp_intended, sp_slip]:
if sp == 4:
R[s, a, sp] = 1.0
elif sp == 0:
R[s, a, sp] = -1.0
else:
R[s, a, sp] = living_cost
# --------
# One-Step Bellman Backup: Q(s,a)
# --------
def compute_Q(V: np.ndarray) -> np.ndarray:
"""
Q[s,a] = sum_{s'} Tau(s'|s,a) * ( R(s,a,s') + gamma * V(s') )
"""
Q = np.zeros((S, A))
for s in range(S):
for a in range(A):
Q[s, a] = np.sum(Tau[s, a, :] * (R[s, a, :] + gamma * V))
return Q
# --------
# Value Iteration
# --------
def value_iteration(tol: float = 1e-8, max_iters: int = 10_000):
V = np.zeros(S)
for _ in range(max_iters):
Q = compute_Q(V)
V_new = V.copy()
for s in range(S):
if is_terminal(s):
V_new[s] = 0.0
else:
V_new[s] = np.max(Q[s])
if np.max(np.abs(V_new - V)) < tol:
V = V_new
break
V = V_new
# Extract greedy policy
Q_final = compute_Q(V)
pi = np.zeros(S, dtype=int)
for s in range(S):
if is_terminal(s):
pi[s] = 0
else:
pi[s] = np.argmax(Q_final[s])
return V, pi
# --------
# Display the Policy with the Values
# --------
def action_name(a: int) -> str:
return "L" if a == LEFT else "R"
create_TauR()
V, pi = value_iteration()
print("VALUE ITERATION SOLUTION:")
print("----------")
for s in range(S):
if is_terminal(s):
print(f"s={s}: V={V[s]: .6f} terminal")
else:
print(f"s={s}: V={V[s]: .6f} pi = {action_name(pi[s])}")
print("----------")
print("The Policy is:")
print(pi)
OUTPUT:
VALUE ITERATION SOLUTION:
----------
s=0: V= 0.000000 terminal
s=1: V= 0.321372 pi = R
s=2: V= 0.728121 pi = R
s=3: V= 0.930343 pi = R
s=4: V= 0.000000 terminal
----------
The Policy is:
[0 1 1 1 0]Explanation of the Output
Now, as a recap, our goal at a high level was simple: guide the agent to the treasure without stepping on the trap and becoming immobilised. Recall that, by definition, we set all terminal states to have value \(V^{\pi} = 0\) - similar to a Dirichlet-style boundary condition.
So, from this, our task was to recover an optimal policy, which is just a mapping from states to actions that maximises the agent’s expected, discounted future rewards. Also, an important side note: this policy need not be unique. There can be multiple paths that lead to the same optimal outcome - as we find to be true in life.
Looking at the output, we first see that the terminal states \(s=0\), and \(s=4\), the trap and the treasure, respectively, both have values equal to zero, exactly as defined. The lowest non-terminal value appears at \(s=1\). Intuitively, this makes sense since this is the most dangerous place to be for the agent. From here, the agent is close to the trap, and the 20% slip probability introduces a high risk of becoming immobilised. As a result, the optimal action in this state is to move RIGHT, away from danger.
At \(s=2\), our Dr Jones is further from the trap and closer to the treasure. The risk has dropped, and so the value of the state increases. Taking another step RIGHT to \(s=3\) yields the highest value among the non-terminal states: the agent is now as far from the trap as possible and one step away from the goal. From here, a final move to the right delivers the agent into the desired terminal state - the treasure!!
In other words, the optimal policy is rather simple: from any non-terminal state, go right until you reach the treasure.
Now what makes this result quite satisfying is that it didn’t come from the designer hard-coding the agents of the action (which would be glaringly obvious when looking at this problem); or trial-and-error’ing’ the solution in a more complicated scenario…instead the behaviour of the agent resulted from the mathematics - effectively, from repeatedly applying the Bellman optimality operator to our value function. I want to delve into the mathematics a bit more now:
At each state, we are asking the following question: “if I was standing in this state, and I could choose the best possible action, what is the maximum expected return that I could obtain from here onward?” This question is encoded into the Bellman optimality equation, which is defined as: \[ V^*(s) = \max_{a \in \mathcal{A}} \sum_{s' \in \mathcal{S}} \tau(s' \mid s, a)\,\big[ R(s, a, s') + \gamma V^*(s') \big] \]
In the code, I broke this up into two separate computations for simplicity:
First, I computed the action-value function, defined as: \[ Q(s,a) = \sum_{s' \in \mathcal{S}} \tau(s' \mid s, a)\,\big[ R(s, a, s') + \gamma V(s') \big] \]
This can be interpreted as the agent saying: ‘for each action, I’ll average over all possible next states and obtain a value weighted by the immediate reward, and the discounted value of future rewards.’
Then, for each state, I applied the Bellman Optimality operator, which yields:
\[ V_{\text{new}}(s) = \max_{a \in \mathcal{A}} Q(s,a) \]
i.e. we only keep the best possible action that promises the highest expected return.
Each iteration shrinks the gap between our current estimate, \(V\) and the true optimal value function \(V^{*}\). The reason for this is that the Bellman Operator is a contraction mapping, for \(\gamma \in [0,1)\) (which just means that values are being pulled closer and closer together). From this, we can apply the Banach fixed-point theorem (which is why one has to show that the operator one uses, is actually a contraction mapping), to show repeated application of the Bellman operator converges to a unique fixed point, which is \(V^{*}\).
Now once we check that the values were within a very small tolerance of each other, we can just extract the policy out from there. We simply fix a state, take the most current \(V^{*}\), and then figure out the action that achieved the maximum value such that:
\[ \pi^*(s) = \arg\max_{a \in \mathcal{A}} Q(s,a) \]
Conclusion
This was the first toy example I implemented which allowed me to gain a better understanding of the theory in practice.
Moreover, it is important to realise that the dynamic programming algorithm is not feasible for large MDPs, given the effective computational complexity of order \(O(|S|^2|A|)\) (as during the Bellman backup step, for each state and action, we need to sum over all possible next states).
I look forward to continuing my learning and pushing this framework beyond a single corridor, into settings where the state space is much larger, the dynamics are unknwon and the structure has to be learned rather than assumed.
Temporal Difference Learning - c’est parti!
References
- Albrecht, S. V., Christianos, F., & Schäfer, L. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024.
- Sutton, R. S., & Barto, A. G. Reinforcement Learning: An Introduction